THE IMPORTANCE OF SECURITY
This post is the third in a series of posts about getting up and running with a Magpie Data Lake. In previous blog posts, we’ve discussed rapidly prototyping a data lake with Magpie, and automating loads into a data lake with Magpie. This post will address a third important piece of data lake infrastructure: security and auditing.
Security is absolutely critical in data lakes, since a data lake oftentimes contains the majority of an organization’s data. Giving users access to the data they need to do their job should not necessarily mean giving them access to all of the data in the lake. Unfortunately, many data lake tools, especially custom do-it-yourself (DIY) implementations, do not provide an easy way to manage and audit data access.
In Magpie, security is a core concept, where every user action is verified and logged for future review. In this post, we’ll demonstrate how to create roles, manage permissions, and audit access in Magpie, using the lake from the last post as a starting point.
CONFIGURING ROLES AND PERMISSIONS
In Magpie, an organization is the top-level metadata structure. Organizations have users, roles, and repositories. Repositories are where data sources, schemas, and job projects reside. Organization administrators are able to manage all aspects of the organization, including creating security roles, assigning permissions to those roles, and granting those roles to users.
As an organization admin, creating a role is easy. For example, say an organization wanted to grant their data science team access to the lake. First, we create a role for the team:
create role {
"name": "data_science",
"description": "The data science team"
}
Then, we can grant the team access read access to all of the data they need:
grant use on repository production_lake to role data_science; grant read on schema transactions to role data_science; grant read on schema web_metrics to role data_science; grant use on schema census to role data_science; grant read on table census.dc_census_data to role data_science;
We can also create a schema for them to use as an analytics sandbox, to save and share analytical results, and grant them access to create new tables in that schema and read other users tables in the schema. Additionally, we grant them use access to the lake’s default data source, which allows the team to use that data source to persist their analytical results:
create schema {
"name": "data_science",
"description": "Data science sandbox schema"
};
grant create on schema data_science to role data_science;
grant read on schema data_science to role data_science;
grant use on data source default_s3_source to role data_science;
Finally, we grant the role to the team members:
grant role data_science to user jon@silect.is; grant role data_science to user brendan@silect.is; grant role data_science to user matt@silect.is;
And, now when we describe the role, we can see both the members of the role and the permissions that are granted to those members:
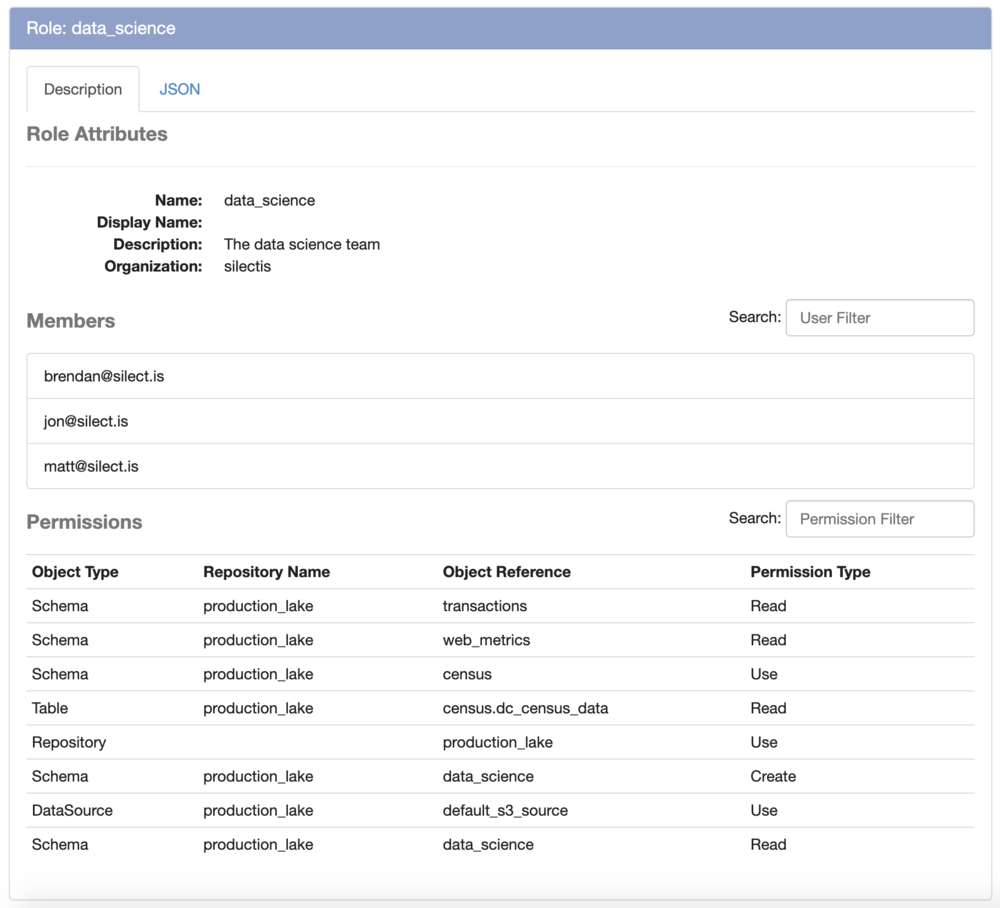
AUDITING ACCESS
With many people in an organization likely to be using a data lake for important analysis, it’s important to be able to track who has accessed or changed data and when it happened. If there is an issue with the quality of a table, auditing can help forensically identify who last modified the table, when, and how. Additionally, auditing can be used to help an organization monitor for unusual data access, or report on data access for compliance purposes. This important feature can be easily overlooked when developing a DIY data lake, and complicated to implement.
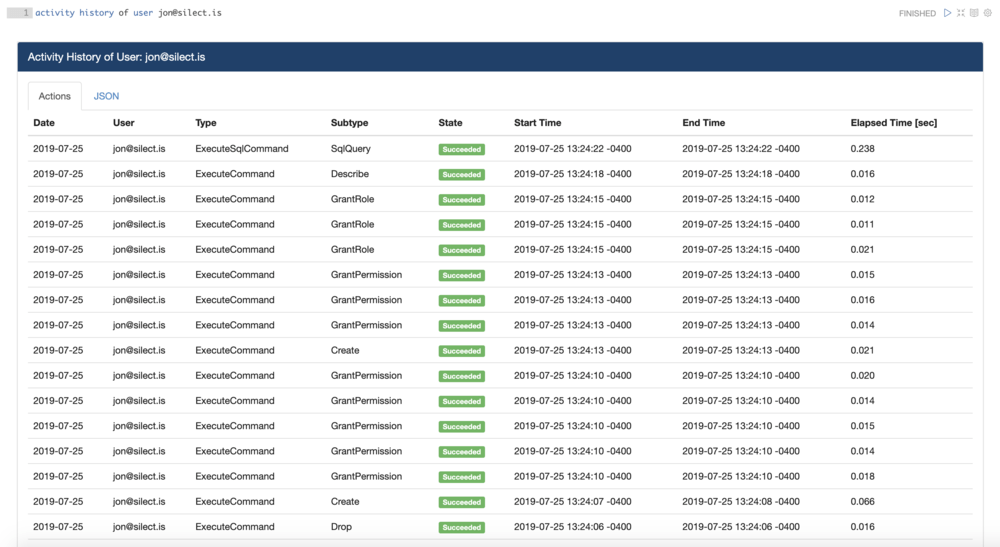
In Magpie, the first way that access can be audited is at the organization or user level. Using the Activity History command, organization admins can see all of the commands run by a given user or the entire organization, and what data each of those commands accessed. For example, auditing my activity, we can see the commands I ran previously in this post, setting up the lake, creating roles, and granting permissions:
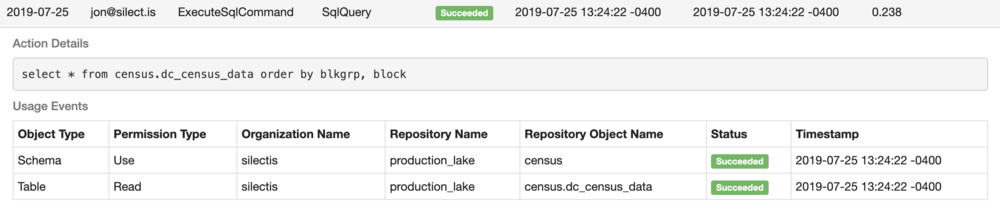
We can also see that I recently ran a SQL query. Diving into that query, we can see that it required read access to the DC Census Data table in the Census schema, and we can see what the query text was:
Failed commands are also logged. This can either be due to a lack of permissions, or an error in execution. For a lack of permissions, those failed accesses are logged in the command history.
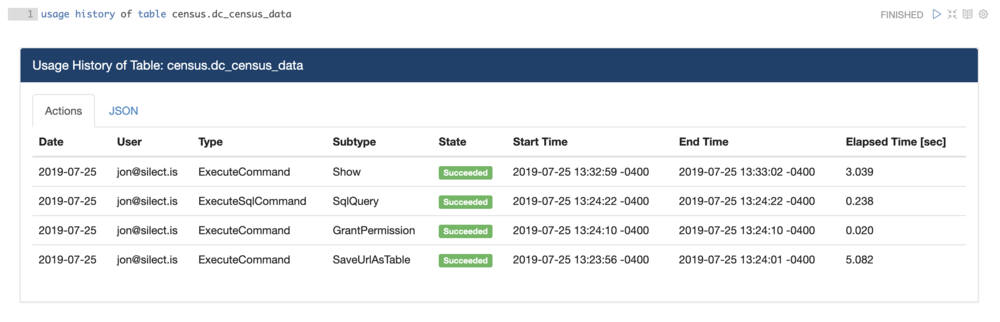
In addition to this targeted user activity auditing, usage history of metadata can be queried. For example, using the Usage History command on the DC Census Data table shows when it was created, when permission was granted to it, and the SQL query and show commands that I ran on it:
DEPLOYING A SECURE DATA LAKE
With all of the different data sources and methods of data access available, ensuring your data lake is secure and can be regularly audited can be a daunting task. This is one of the many reasons to use a data lake platform, rather than trying to go it alone.
If your organization is interested in setting up a secure data lake and wants to get up and running as quickly as possible, click here to see how Magpie can help.
Jon Lounsbury is the Vice President of Engineering at Silectis.
You can find him on Github.